Biography
I am a researcher at Alibaba Tongyi Lab, where I lead Z-Image's reinforcement learning alignment. My work mainly focuses on foundation model post-training, spanning SFT, RL, and training infrastructure, while also contributing to pre-training for advanced model capabilities. My research centers on multimodal generation and understanding. Earlier, I worked on multimodal large language models at Tencent Hunyuan, with a focus on improving their advanced reasoning capabilities.
News
- 2026 Released Z-Reward, a reasoning-internalized teacher-student reward modeling framework for text-to-image post-training.
- 2026 Released Z-Image (Base), the high-quality foundation model specializing in rich aesthetics and controllability. The series is now the #2 most popular Chinese model on Hugging Face and ranks 2nd in global Image Generation API usage on fal.ai.
- 2025 Released Z-Image-Turbo, an efficient 6B foundation model specializing in photorealistic image generation. It ranked #1 among open-source text-to-image models on the Artificial Analysis Image Arena, while achieving sub-second inference latency.
- 2024 Released MM-IQ, a new benchmark for assessing the core reasoning capabilities of large multimodal models.
- 2024 New paper on Self-Correction in LLMs released on arXiv.
- 2024 Paper System-2 Mathematical Reasoning accepted to TMLR.
- 2023 The extended paper Tri-token Equipped Transformer Model for Image Matting released on arXiv.
- 2022 TransMatting accepted to ECCV.
- 2021 Won the 2nd Place Award in NTIRE 2021 Challenge on Multi-modal Aerial View Object Classification at CVPR 2021.
Publications
* Equal contribution. † Project Lead. Representative papers are highlighted.
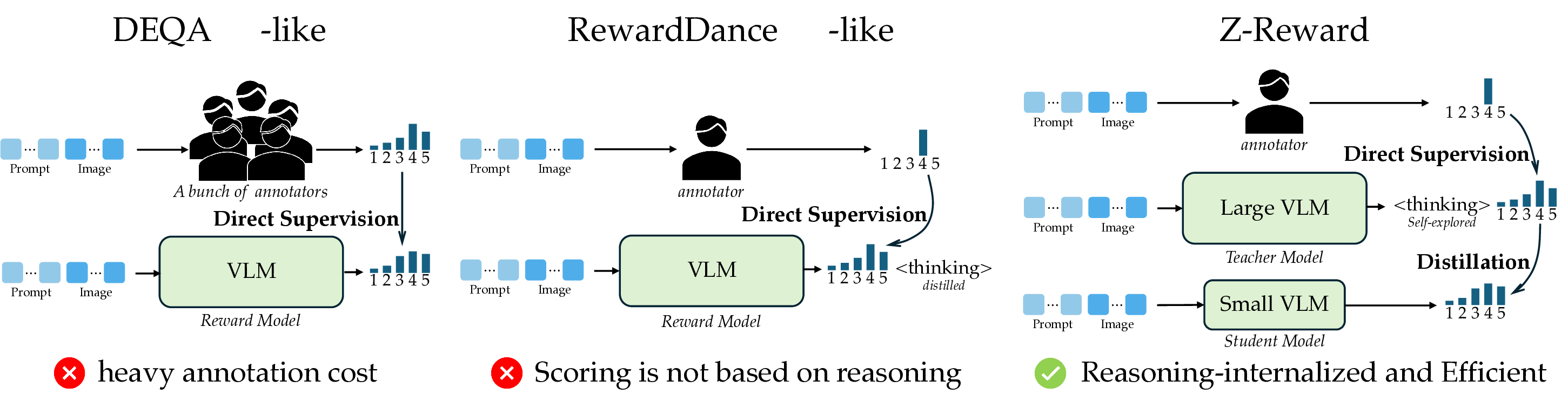
Z-Reward: Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions
Tech Report, 2026
Role: Project Lead.
Z-Reward is a reasoning-internalized reward modeling framework for visual generation. It decouples reasoning-heavy judgment from efficient reward deployment: a 27B GDSO teacher reasons over rubric-aligned score distributions, while a compact 9B RISD student internalizes the teacher's distributional judgment without generating explicit reasoning chains at inference time.


Tech Report, 2025
Z-Image is a state-of-the-art foundation model designed for high efficiency.
Community Impact: It is the #2 most popular Chinese model on Hugging Face and ranks 2nd in global API usage on fal.ai (next to Gemini Nano). It excels at generating photorealistic images with superior visual quality while maintaining low computational cost.
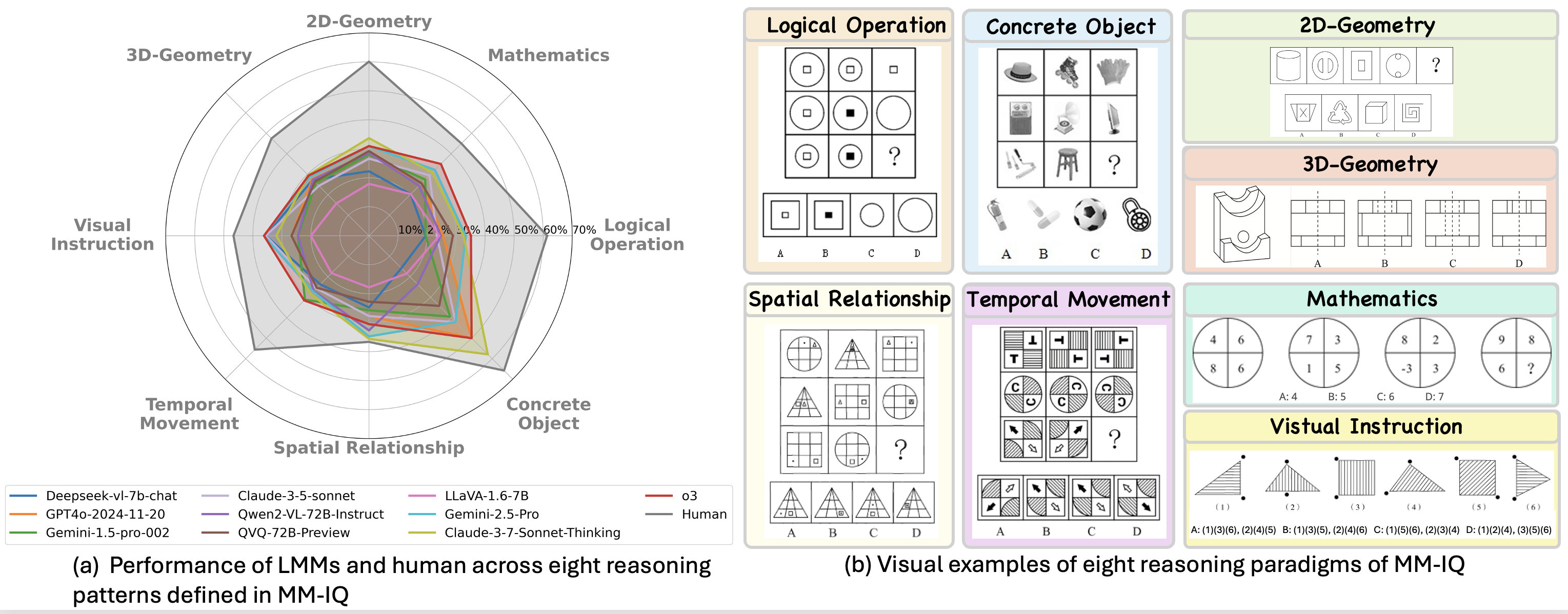
MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models
arXiv Preprint, 2024
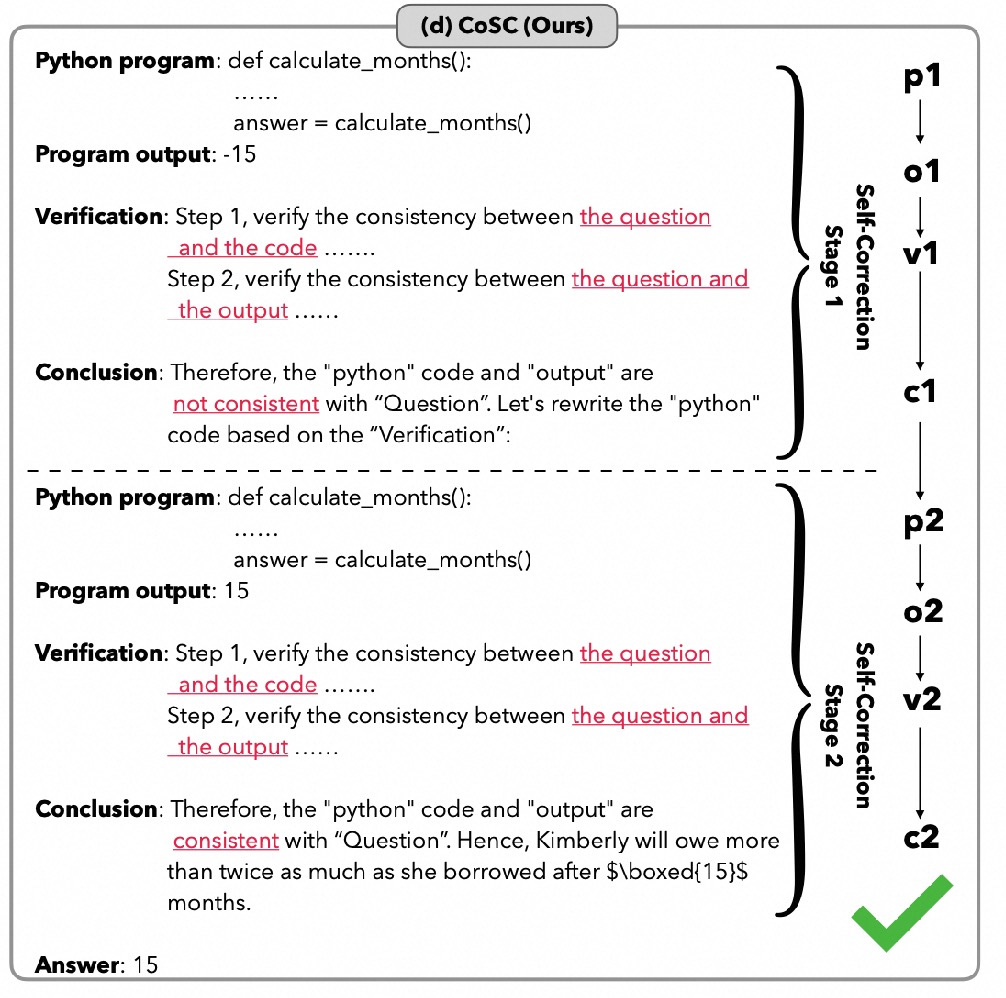
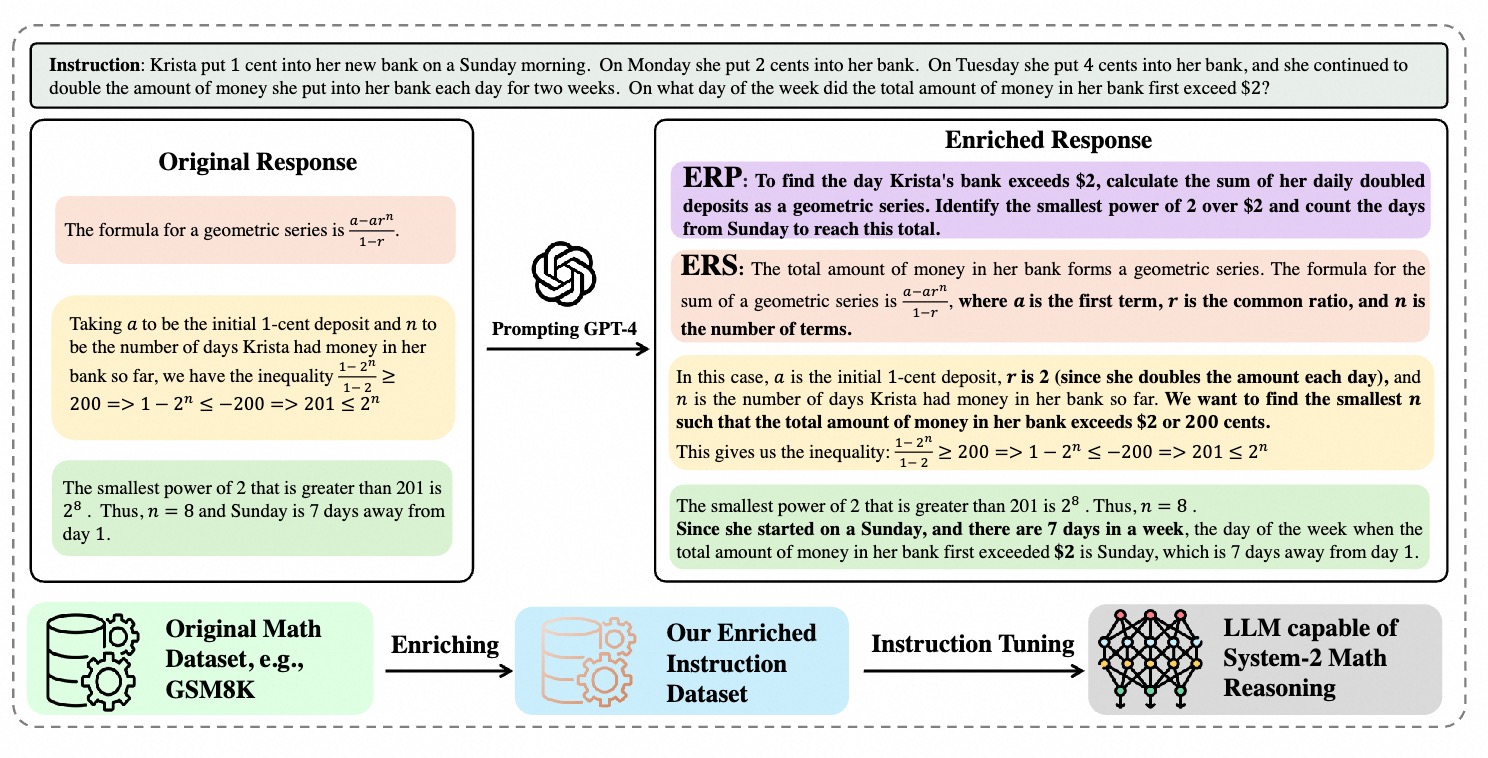
System-2 Mathematical Reasoning via Enriched Instruction Tuning
Transactions on Machine Learning Research (TMLR), 2024
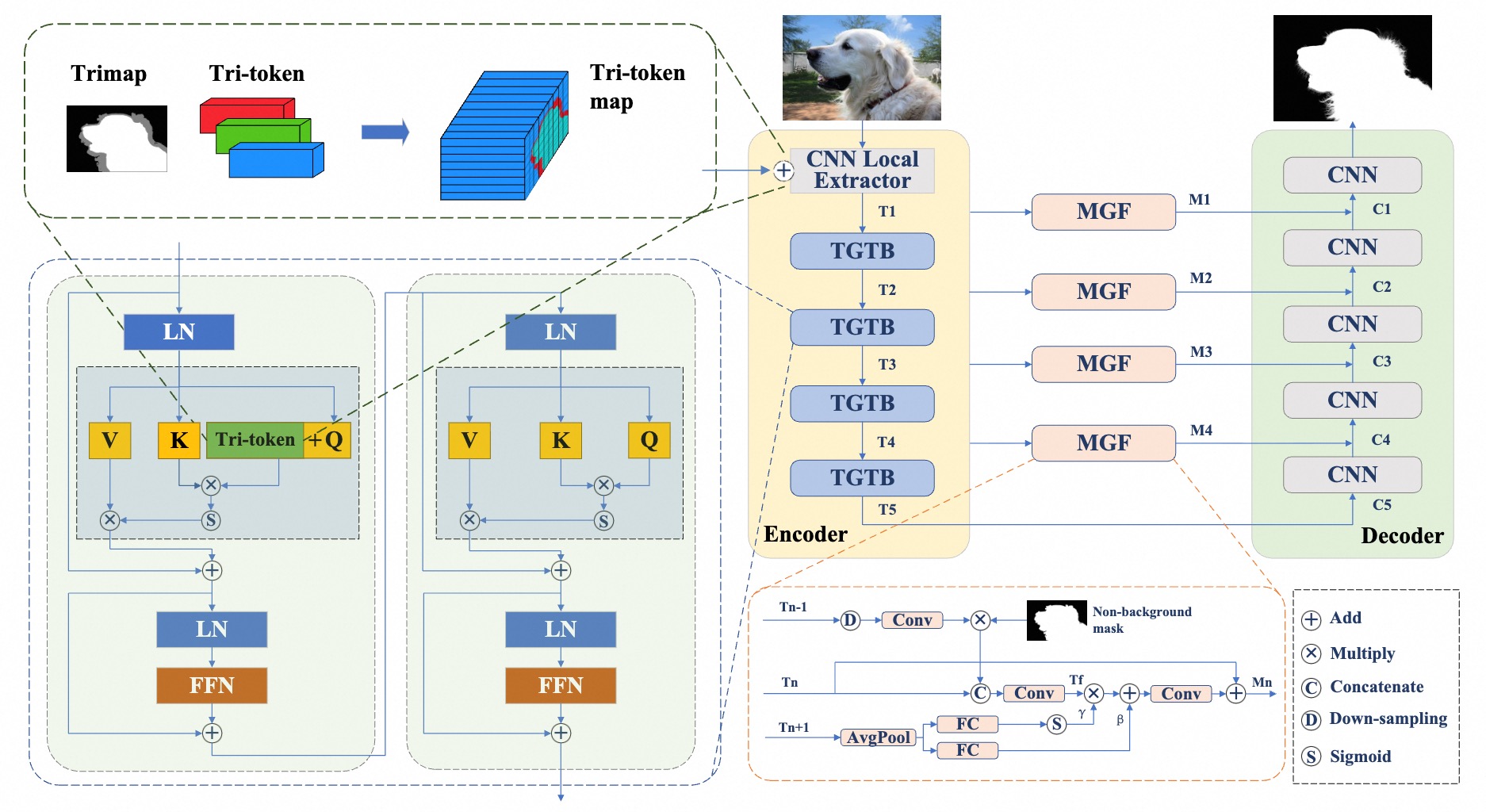
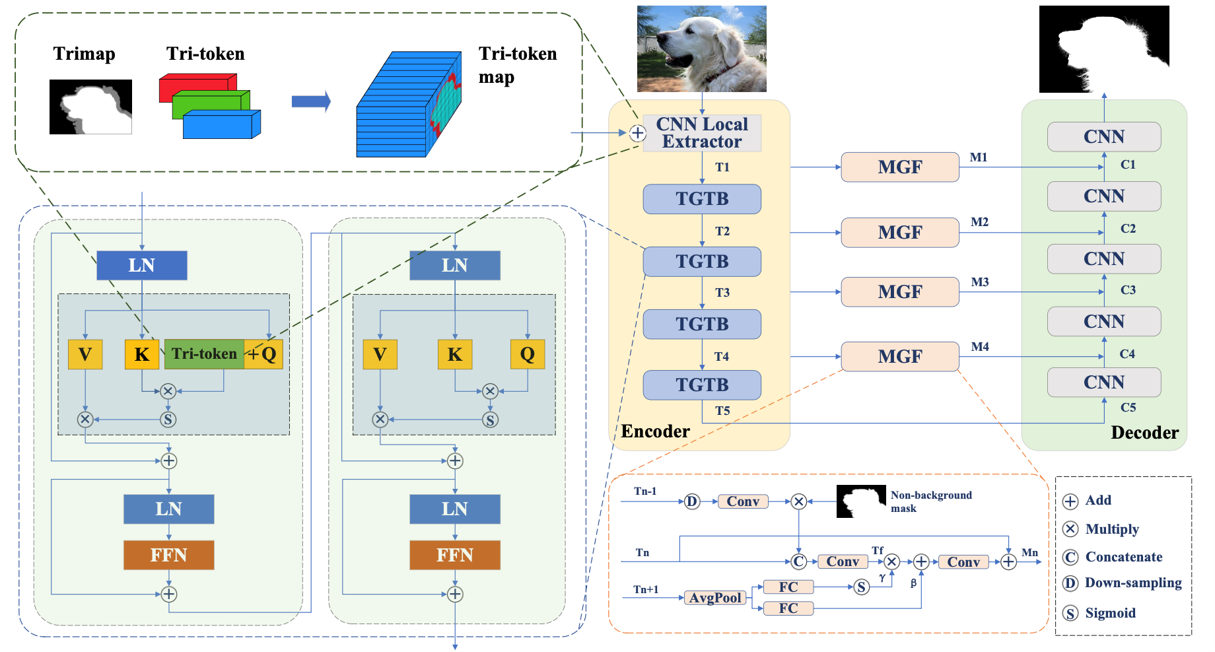
TransMatting: Enhancing Transparent Objects Matting with Transformers
European Conference on Computer Vision (ECCV), 2022